


新华网北京10月22日电(记者张漫子)北京智源人工智能研究院21日发布原生多模态世界模型Emu3。该模型能够实现视频、图像、文本三种模态的统一理解与生成,验证了基于下一个词元(token)预测的多模态技术范式,展现了其在大规模训练与推理方面的潜力。
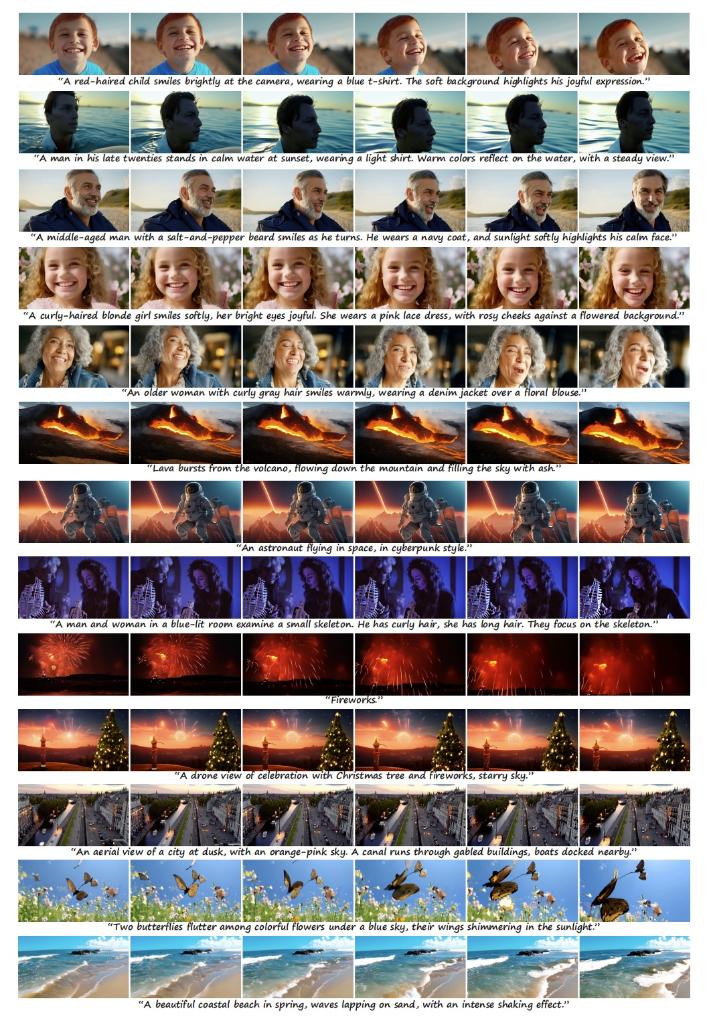
图为原生多模态世界模型Emu3文生视频过程帧画面展示(采访对象供图)
当前,行业现有的多模态大模型多为对于不同任务而训练的专用模型,如Stable Diffusion之于文生图,Sora之于文生视频,GPT-4V之于图生文。现有模型的能力多为单一分散的能力组合,而不是原生的统一能力,比如目前Sora还做不到图像和视频的理解。
多模态大模型亟需将理解、生成等统一在一个模型里。此次发布的多模态世界模型Emu3仅基于下一个词元(token)预测,无需扩散模型或组合式方法,把图像、文本和视频编码为一个离散空间,并通过自回归的方式进行统一训练。这相当于为文字、图像、视频发明了一种统一“新语言”,可在同一空间中进行表达。
“这一简单的架构设计能为大规模的多模态训练和推理提供基础,有利于产业化。同时,该训练技术能够更大程度复用现有的训练资源,降低了对新基础设施的需求,从而加速多模态大模型的迭代和落地。未来,多模态世界模型将促进机器人大脑、自动驾驶、多模态对话和推理等场景应用。”北京智源人工智能研究院院长王仲远说。
【纠错】 【责任编辑:毕尚宏】







