


新华网北京9月25日电(记者张漫子)阿里云25日宣布开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费商用。此次开源将显著降低中小企业开发细分领域行业模型的门槛,也标志着阿里云大模型开源生态初具雏形。
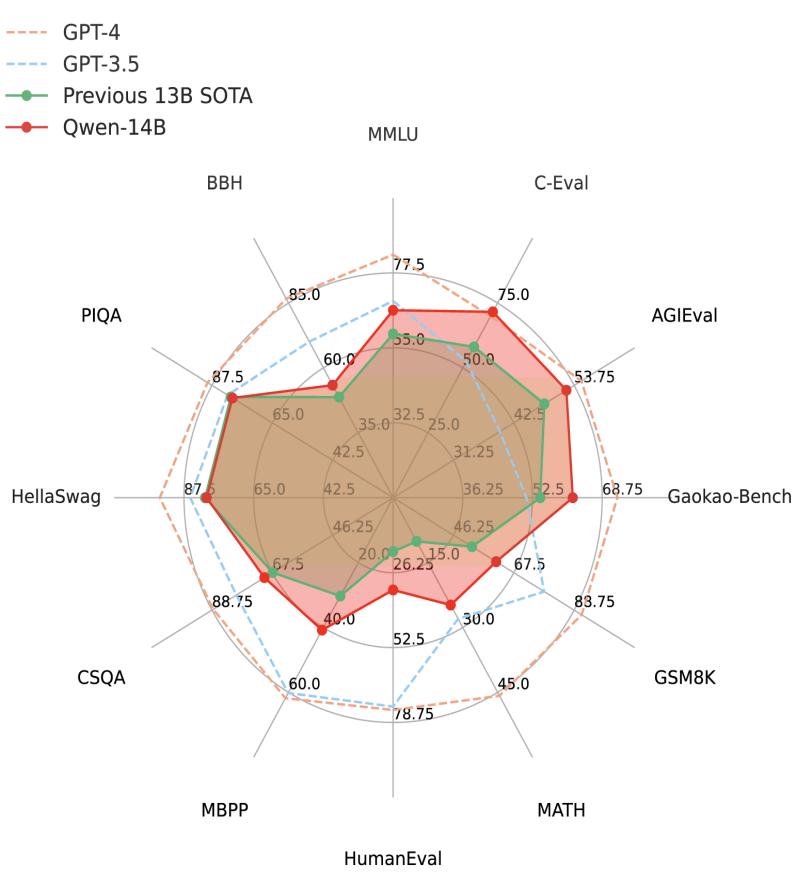
对Qwen-14B进行的十二个测评结果显示,该模型具有更强大的推理、认知、规划、记忆能力。受访者制图
此次开源的基座模型Qwen-14B是一款支持多种语言的高性能开源模型,其亮点是更高质量的数据。
“研发团队使用了多达3万亿文本单元的大规模预训练数据集,覆盖多个领域与行业知识,包含多种语言及代码数据。我们做了更为精细的数据处理,包括大规模数据去重、垃圾文本过滤、提升高质量数据比例等。” 研发人员介绍,基于140亿参数,基座模型具备了更强大的推理、认知、规划、记忆能力。
Qwen-14B-Chat是基于基座模型Qwen-14B的对话模型,生成内容的准确度有了显著提升,在内容创作方面表现出一定的想象力。
“大规模预训练模型参数量大、训练成本高,开源大模型可帮助用户简化模型训练和部署,不必从零开始训练模型,只需下载预训练好的模型并进行微调,即可快速构建高质量模型、进行应用开发。”阿里云相关负责人介绍。
通义千问大模型此次开源后,开发者可用简单指令教会Qwen使用复杂工具,如使用代码解释器进行复杂的数学计算、数据分析、图表绘制等,还能开发具有多文档问答、长文写作等能力的“数字助理”。

据介绍,钉钉、天猫精灵等阿里巴巴所有产品均将接入通义千问大模型,并进行全面改造。阿里云牵头建设的魔搭社区目前已累计集聚230多万名开发者,并已有30多家人工智能机构贡献1200多个开源模型。
【纠错】 【责任编辑:毕尚宏】







